


1、分布式id解决方案
1.1、分类
我们所能够了解到的解决方案有以下几种
- UUID
- 数据库自增ID
- 数据库多主模式
- 号段模式
- Redis原子性自增
- 雪花算法(SnowFlake)
- 滴滴出品(TinyID)
- 百度 (Uidgenerator)
- 美团(Leaf)
事实上,实用的方案总结起来就是三种
- 数据库自增
- 数据库自增演变的号段模式
- 雪花算法
2、雪花算法
2.1、雪花算法介绍
2.1.1、什么是雪花算法
雪花算法是Twitter公司发明的一种算法,主要目的是解决在分布式环境下,ID怎样生成的问题
特点:
- 分布式情况下多机器生成id不重复(id不能重复)
- long类型单调自增(单调递增的整形便于索引)
- 高并发(并发的情况下也能够使用)
- id不连续(如果连续,容易被计算出数量,比如用户数量)
其优点
- 经测试snowflake每秒能生成26万个自增可排序的ID
- snowflake生成的ID结果是一个64bit大小的整数,为一个Long型 (转换成字符串后长度最多19)
- 分布式系统内不会产生ID碰撞(datacenter和workerId作区分)并且效率高
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也非常高,可以根据自身业务分配bit位,非常灵活
2.2.1、雪花算法结构
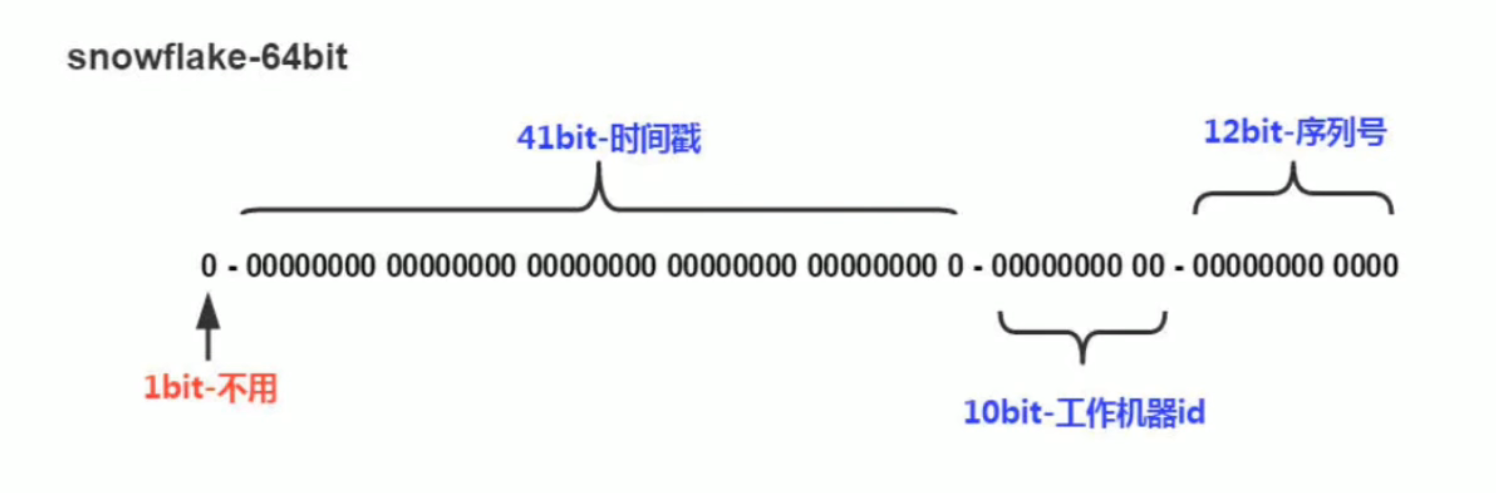
- 第一个部分,是1个bit:0,这个是无意义的
- 因为二进制里第一个bit为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个bit统一都是0
- 第二个部分是 41 个 bit:表示的是时间戳
- 41 bit 可以表示的数字多达 2^41 - 1,也就是可以标识 2 ^ 41 - 1 个毫秒值,换算成年就是表示 69 年的时间
- 第三个部分是10个bit:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。
- 但是 10 bit 里 5 个 bit 代表机房 id,5 个 bit 代表机器 id。意思就是最多代表 2 ^ 5 个机房(32 个机房),每个机房里可以代表 2 ^ 5 个机器(32 台机器),也可以根据自己公司的实际情况确定。
- 第五个部分是 12 个 bit:这个是用来记录同一个毫秒内产生的不同id
- 12 bit 可以代表的最大正整数是 2 ^ 12 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 id
为了保证id的唯一性,我们是通过第二个部分的时间戳来保证了。那么这一部分的时间戳为当前的时间减去我们设置的时间的差值。比如说我设置起始时间为2022年1月1日,那么使用当前时间减去2022年1月1日时间戳,来保证每个毫秒生成的id唯一。但是这里会出现一个问题,那就是如果我动了设置的其实时间,那么时间差值就会发送改变,而可能造成生成id重复。这就是传统雪花算法所没有解决的问题,时间回拨
2.2.2、雪花算法问题
- 生成的ID太长。
- 主键值太长,超过前端 js Number 类型最大值,须把 Long 型转换为 String 型
- 瞬时并发量不够。
- 不能解决时间回拨问题。
- 不支持后补生成前序ID(时间回拨问题)。
- 可能依赖外部存储系统。
2.2、优化雪花算法
事实上,传统的雪花算法是有一些缺点的,那么我们可以优化传统雪花算法的缺点么?
2.2.1、需求分析
做为架构设计的你,想要解决数据库主键惟一的问题,特别是在分布式系统多数据库中。
你但愿数据表主键用最少的存储空间,索引速度更快,Select、Insert 和 Update 更迅速。
你要考虑在分库分表(合库合表)时,主键值可直接使用,并能反映业务时序。
若是这样的主键值太长,超过前端 js Number 类型最大值,须把 Long 型转换为 String 型,你会以为有点沮丧。
尽管 Guid 能自增,但占用空间大,索引速度慢,你不想用它。
应用实例可能超过50个,每一个并发请求可达10W/s。
要在容器环境部署应用,支持水平复制、自动扩容。
不想依赖 redis 的自增操做得到连续的主键ID,由于连续的ID存在业务数据安全风险。
你但愿系统运行 100 年以上。
2.2.2、新算法优势
- 整形数字,随时间单调递增(不必定连续),长度更短,用50年都不会超过 js Number类型最大值。(默认配置)
- 速度更快,是传统雪花算法的2-5倍,0.1秒可生成50万个(基于8代低压i7)。
- 支持时间回拨处理。好比服务器时间回拨1秒,本算法能自动适应生成临界时间的惟一ID。
- 支持手工插入新ID。当业务须要在历史时间生成新ID时,用本算法的预留位能生成5000个每秒。
- 不依赖任何外部缓存和数据库。(k8s环境下自动注册 WorkerId 的动态库依赖 redis)
- 基础功能,开箱即用,无需配置文件、数据库链接等。
2.2.3、性能分析
(参数:10位自增序列,1000次漂移最大值)
| 连续请求量 | 5k | 5K | 50K |
|---|---|---|---|
| 传统雪花算法 | 0.0045s | 0.053s | 0.556s |
| 雪花漂移算法 | 0.0015s | 0.012s | 0.113s |
极致性能:500W/s~3000W/s。(全部测试数据均基于8代低压i7计算)
2.2.4、id组成
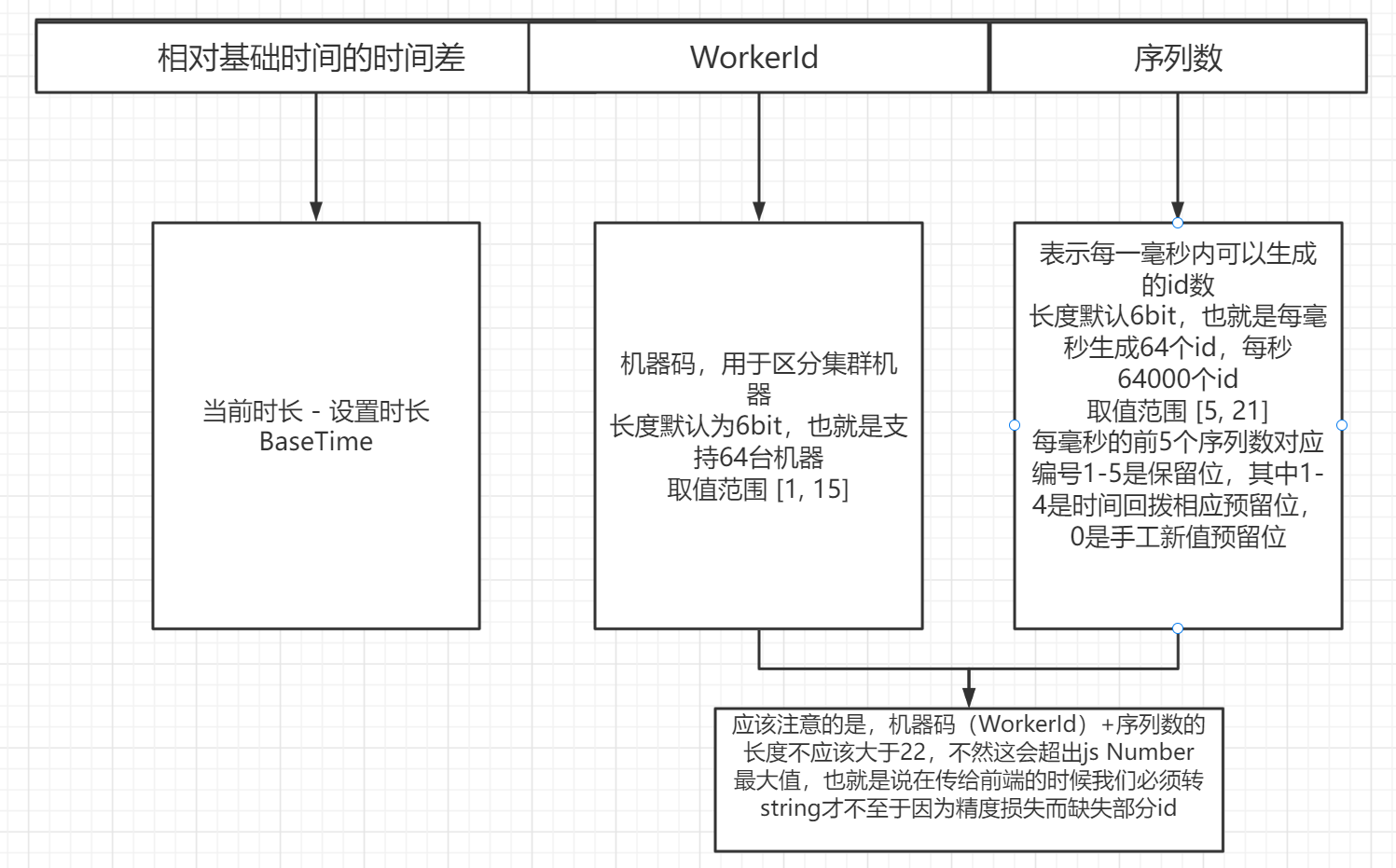
js Number 类型最大数值:9007199254740992,本算法在保持并发性能(5W+/0.01s)和最大64个 WorkerId(6bit)的同时,能用70年才到 js Number Max 值。
2.2.5、思考
我们在做分布式id生成的时候,他并不能保证全局的一个单调递增,这也包括分段id生成的方法,而是一个趋势递增。
事实上,我们做id生成是不需要保证id递增的。索引本身内部可以理解为排序了的数据结构。当我们执行插入操作的时候,会先将数据插入表中,再插入索引表。那我们知道,建立索引的目的就是为了便于搜索,而mysql索引底层是B+数实现的,那么在插入的时候实际上也会进行一次搜索过程。因此,保证单调递增的id生成并没有什么意义。
保证趋势递增只是因为时间戳生成id的一个特性,并没有什么实际意义。
2.2.6、时间回拨
时间回拨问题是雪花算法中经典的问题,描述如下。
雪花算法依赖采用系统时间 - 设定基本时间生成第一部分数据,但是系统时间并不一定准确,当机器与远端时间同步器进行同步的时候,有可能系统时间发生了回溯,比如说我现在系统时间是2022-6-1 18:00:02,这个时候操作系统从远端服务器同步了一下时间,结果现在系统时间变成了2022-6-1 18:00:00,那我们知道,雪花算法时间是不允许回溯,这个时候就可能会产生相同id。这就是时间回拨问题。
如何解决呢?
-
直接抛出异常:不可取,阻塞接口了。
-
延迟等待:与上面一样,阻塞堆积接口,可能会照成oom
-
备用机:不是很好,雪花算法本身就是为了单机上面自己生成而去中心化
-
采用之前最大时间:可以
-
预留序列段:可以,在每毫米生成预留一段用于时间回拨处理,但会消耗部分id
3、号段模式
3.1、号段模式介绍
事实上,分布式id解决方案在高可用的前提下就只剩下雪花算法和号段模式了。这里我们将仔细聊一聊号段模式。
美团的分布式id生成器Leaf是一个经典的号段模式生成分布式id(虽然他也支持雪花)。
3.1.1、工作流程
前面提到了号段模式作为数据库自增的增强版。在传统的数据库自增在高并发的情况下,不断地请求数据库获取自增id,会直接打挂数据库。
所谓号段模式,就是一次请求批量的id,以降低数据库的负载。而所谓的leaf,就是以观察者模式这一设计模式为理念。向数据库一批一批的请求id,并分发出去给需要的服务。当然,leaf也可以部署多个,用于分布式架构
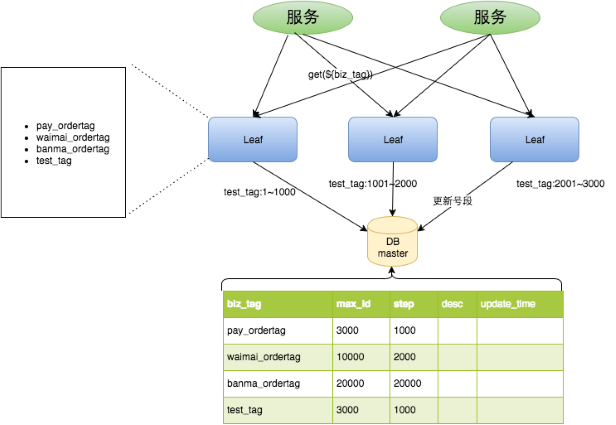
- Leaf Server 1:从DB加载号段[1,1000]。
- Leaf Server 2:从DB加载号段[1001,2000]。
- Leaf Server 3:从DB加载号段[2001,3000]。
用户通过Round-robin的方式调用Leaf Server的各个服务,所以某一个Client获取到的ID序列可能是:1,1001,2001,2,1002,2002……也可能是:1,2,1001,2001,2002,2003,3,4……当某个Leaf Server号段用完之后,下一次请求就会从DB中加载新的号段,这样保证了每次加载的号段是递增的。
当然,我们需要一个数据库,字段如下
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT '业务key',
`max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT '当前已经分配了的最大id',
`step` int(11) NOT NULL COMMENT '初始步长,也是动态调整的最小步长,每次请求的id数量',
`description` varchar(256) DEFAULT NULL COMMENT '业务key的描述',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '数据库维护的更新时间',
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3.1.2、高可用优化
3.1.2.1、双Buffer优化
上述方案非常的完善,但是出现了以下几个问题
- 在更新DB的时候会出现耗时尖刺,系统最大耗时取决于更新DB号段的时间。
- 当更新DB号段的时候,如果DB宕机或者发生主从切换,会导致一段时间的服务不可用。
为了解决这两个问题,Leaf采用了异步更新的策略,同时通过双Buffer的方式,保证无论何时DB出现问题,都能有一个Buffer的号段可以正常对外提供服务,只要DB在一个Buffer的下发的周期内恢复,就不会影响整个Leaf的可用性。
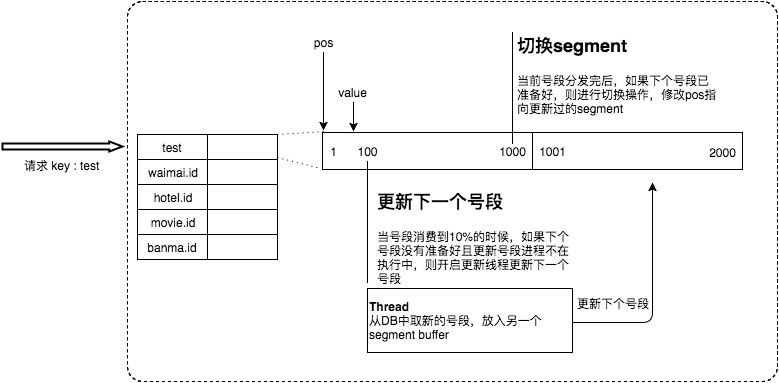
简单的说就是当当前请求的号段用了10%的时候,就会去数据库请求下一批的id,并且缓存起来。
3.1.2.2、动态调整step
当然,出现了新问题
- 号段长度始终是固定的,假如Leaf本来能在DB不可用的情况下,维持10分钟正常工作,那么如果流量增加10倍就只能维持1分钟正常工作了。
- 号段长度设置的过长,导致缓存中的号段迟迟消耗不完,进而导致更新DB的新号段与前一次下发的号段ID跨度过大。
为此设计了动态调整step步长,也就是动态的调整每次向数据库请求id的数量
假设服务QPS为Q,号段长度为L,号段更新周期为T,那么Q * T = L。最开始L长度是固定的,导致随着Q的增长,T会越来越小。但是Leaf本质的需求是希望T是固定的。那么如果L可以和Q正相关的话,T就可以趋近一个定值了。所以Leaf每次更新号段的时候,根据上一次更新号段的周期T和号段长度step,来决定下一次的号段长度nextStep:
- T < 15min,nextStep = step * 2(当前生成数量15分钟之内用完,下次数量翻倍)
- 15min < T < 30min,nextStep = step(当前生成数量十五分钟到30分钟之内用完,下次数量不变)
- T > 30min,nextStep = step / 2(当前生成数量30分钟还没用完,下次数量减半)
至此,满足了号段消耗稳定趋于某个时间区间的需求。当然,面对瞬时流量几十、几百倍的暴增,该种方案仍不能满足可以容忍数据库在一段时间不可用、系统仍能稳定运行的需求。因为本质上来讲,Leaf虽然在DB层做了些容错方案,但是号段方式的ID下发,最终还是需要强依赖DB。
评论区